Hadoop学习笔记(六)Yarn
【这个写的很好】https://github.com/heibaiying/BigData-Notes/blob/master/notes/Hadoop-YARN.md
Apache YARN (Yet Another Resource Negotiator) 是 hadoop 2.0 引入的集群资源管理系统。用户可以将各种服务框架部署在 YARN 上,由 YARN 进行统一地管理和资源分配。
一、架构
1.1 ResourceManager
ResourceManager 通常在独立的机器上以后台进程的形式运行,它是整个集群资源的主要协调者和管理者。ResourceManager 负责给用户提交的所有应用程序分配资源,它根据应用程序优先级、队列容量、ACLs、数据位置等信息,做出决策,然后以共享的、安全的、多租户的方式制定分配策略,调度集群资源。
1.2 NodeManager
NodeManager 是 YARN 集群中的每个具体节点的管理者。主要负责该节点内所有容器的生命周期的管理,监视资源和跟踪节点健康。具体如下:
- 启动时向
ResourceManager注册并定时发送心跳消息,等待ResourceManager的指令; - 维护
Container的生命周期,监控Container的资源使用情况; - 管理任务运行时的相关依赖,根据
ApplicationMaster的需要,在启动Container之前将需要的程序及其依赖拷贝到本地。
1.3 ApplicationMaster
在用户提交一个应用程序时,YARN 会启动一个轻量级的进程 ApplicationMaster。ApplicationMaster 负责协调来自 ResourceManager 的资源,并通过 NodeManager 监视容器内资源的使用情况,同时还负责任务的监控与容错。具体如下:
- 根据应用的运行状态来决定动态计算资源需求;
- 向
ResourceManager申请资源,监控申请的资源的使用情况; - 跟踪任务状态和进度,报告资源的使用情况和应用的进度信息;
- 负责任务的容错。
1.4 Container
Container 是 YARN 中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等。当 AM 向 RM 申请资源时,RM 为 AM 返回的资源是用 Container 表示的。YARN 会为每个任务分配一个 Container,该任务只能使用该 Container 中描述的资源。ApplicationMaster 可在 Container 内运行任何类型的任务。例如,MapReduce ApplicationMaster 请求一个容器来启动 map 或 reduce 任务,而 Giraph ApplicationMaster 请求一个容器来运行 Giraph 任务。
二、YARN工作原理简介
用于资源调度,包含ResourceManager和NodeManager。
意义:让Hadoop变得更加通用,让很多的运算框架都能够在YARN集群上跑起来。只要让他们实现AppMaster接口就可以了。

三、job提交流程
job提交流程图:
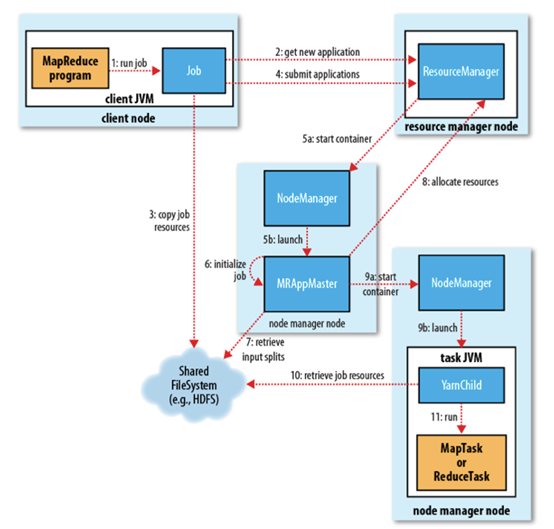
3.1 job提交流程解析
作业的提交
当我们编写好MapReduce程序打成一个jar包,运行Main方法,其中有个job.waitforcompletion()会创建一个客户端实例RunJar。
这个RunJar会找ResourceManager通信,申请执行一个application应用(这里在客户端叫job,在yarn里叫application)。ResourceManager返回application相关资源提交的路径starting-dir(还记得本地模式下那个tmp开头的临时目录吗,就是这个)和为本application产生的applicationID(这步的主要目的就是拿到这个ID)。
RunJar把相应的jar包和配置文件提交到HDFS临时目录下(还记得本地模式下那个/tmp/…/job.xml还有切片信息等吗)。为什么要放在HDFS中?因为HDFS是共享系统,每个节点都能访问到里面的内容。

因为之前运行过一个MR程序,可以查看HDFS文件列表,发现确实有/tmp/…开头目录的文件信息。
最后, 通过调用 submitApplication() 来提交作业到ResourceManager。当资源管理器收到submitApplciation() 的请求时, 就将该请求发给YARN调度器 (scheduler), 让调度器分配一个container。

作业的初始化
- ResourceManager会找到集群中一台NodeManager在其容器(container)中启动程序主进程(MRAppMaster) 由节点管理器监控 (第 5 步)。并向ResourceManager注册,当程序运行完成后,会向ResourceManager注销自己,回收资源。
- 然后MRAppMaster会先去HDFS中检索输入分片。对每一个分片创建一个map任务对象以及通过setNumReduceTasks()方法确定的多个reduce任务对象。(HDFS中有切片信息,这代表了需要多少个并发执行的Map任务。)任务ID在此时分配。
任务的分配
- 如果是小作业,会在自己的JVM上运行。如果是大作业会为该作业中的所有map任务和reduce任务向ResourceManager请求容器(map任务的请求有着数据本地化局限,这也是调度器关注的,着意味着分片和任务在同一节点上运行)
任务的执行
- 一旦ResourceManager的调度器为任务分配了一个特定节点上的容器,MRAppMaster就通过联系节点管理器通信来启动 container(第 9 步)。
- 然后这些NodeManager就会启动yarn子进程(任务由主类为YarnChlid的一个JAVA应用程序执行),但是在运行任务之前,首先要将任务需要的资源本地化,包括作业的配置,jar文件和所有来自分布式缓存的文件。(yarn子进程因为拿到了切片信息,就可以去HDFS检索对应的资源。)
- 拿到资源后就可以开启MapTask或者ReduceTask。
Streaming

Streaming运行特殊的map任务和reduce任务,目的是运行用户提供的可执行程序(就是自己写的MR函数,接受K-V输出K-V),并与之通信。
3.2 YARN工作机制流程图(详细)

YARN应用可以在运行中的任意时刻提出资源申请。比如spark在最开始提出所有的请求,而MapReduce采用动态的方式:在最开始时申请map任务容器,reduce任务容器的启用则放在后期。
四、调度器
4.1 FIFO调度器
有点:简单易懂,不需要任何配置
缺点:不适合共享集群。大的应用会占用集群中所有资源,所以每个应用必须等待直到轮到自己运行(即一个时刻只能有一个任务在运行)

4.2 容量调度器(默认)
hadoop2.7默认使用的是Capacity Scheduler容量调度器。
对于Capacity调度器,有一个专门的队列用来运行小任务,在一个列队里FIFO,但是为小任务专门设置一个队列会预先占用一定的集群资源,这就导致大任务的执行时间会落后于使用FIFO调度器时的时间。(即牺牲整个集群的利用率为代价。因为有一部分被分配给小任务了,不论这里小队列是否有任务在执行,大队列中的任务都不能用到小队列中的资源。如图下job1到job2之间B队列的空闲部分。当然有可能会超出队列容量分配资源,这叫做“弹性队列”)

4.3 公平调度器
不需要预留一定量的资源,因为调度器会在所有运行的作业之间动态平衡资源。举个例子,假设有两个用户A和B,他们分别拥有一个队列。当A启动一个job而B没有任务时,A会获得全部集群资源;当B启动一个job后,A的job会继续运行,不过一会儿之后两个任务会各自获得一半的集群资源。如果此时B再启动第二个job并且其它job还在运行,则它将会和B的第一个job共享B这个队列的资源,也就是B的两个job会用于四分之一的集群资源,而A的job仍然用于集群一半的资源,结果就是资源最终在两个用户之间平等的共享。在Fair调度器中,我们不需要预先占用一定的系统资源,Fair调度器会为所有运行的job动态的调整系统资源。当第一个大job提交时,只有这一个job在运行,此时它获得了所有集群资源;当第二个小任务提交后,Fair调度器会分配一半资源给这个小任务,让这两个任务公平的共享集群资源。
注意,从第二个作业的启动到获得公平共享资源之间会有时间滞后,因为它必须等待第一个作业使用的容器用完并释放出资源。当小作业结束后,不再申请资源,这时候大作业将回去再次使用全部集群资源。

